Snapshot for the Impatient
At 11pm on a Sunday, somewhere a doctoral candidate has sixteen tabs open, three half-written paragraphs, and a deadline that has stopped being polite. The reflex is to type a question into a chatbot. The hard part is picking the one that will save the night without quietly fabricating a citation that survives every spellcheck and dies in peer review.
In 2026, that choice keeps narrowing to two tools. Perplexity, the citation-first answer engine that fetches from live sources before generating a word, and ChatGPT, the long-context reasoning model that synthesizes, drafts, and argues across whole research files. Both cost the same on their headline plans. The work they save, and the work they create, look completely different.
| At-a-glance | Perplexity | ChatGPT |
|---|---|---|
| Headline plan | Pro at $20 per month | Plus at $20 per month |
| Default behavior | Live web search with inline citations | Conversational reasoning from training data |
| Best for | Source discovery, fact verification, literature scoping | Synthesis, drafting, structured argumentation |
| Native academic mode | Academic Focus (Semantic Scholar, 200M plus papers) | None native; Deep Research approximates one |
| Average response latency | 3.8 seconds | 5.4 seconds |
| Citation reliability | Linked, persistent, numbered by default | Inconsistent outside Deep Research mode |
| Hallucination risk profile | About 37 percent incorrect answers (Tow Center) | 20 to 56 percent citation issues across studies |
| Deep Research speed | 2 to 4 minutes per report | 5 to 30 minutes per report |
Both tools are good. Neither is sufficient on its own for thesis-grade work. The interesting question is how to use them together without letting the weaknesses of either contaminate the final paper.
Figure: At-a-glance comparison. Two tools, same headline price, very different roles in a research workflow.

ChatGPT, Stripped to the Academic Use Case
ChatGPT in 2026 is no longer one product. The interface that students opened in 2023 has fragmented into six tiers, each with different Deep Research limits, context windows, and model access. For academic work, three numbers matter above the rest: the model variant, the Deep Research quota, and the context window. Everything else is secondary.
Pricing tiers that actually apply to researchers
| Plan | Monthly cost | Deep Research runs | Model access | Context window | Academic relevance |
|---|---|---|---|---|---|
| Free | $0 | None | GPT-5.3 Instant, 10 messages per 5 hours | Around 16K tokens | Ads in US; no web access; casual study help only |
| Go | $8 | None | Higher message ceiling, basic models | Around 16K tokens | Suitable for note-taking, not literature review |
| Plus | $20 | 10 per month | GPT-5.4 Thinking, Sora, Codex, Agent Mode | Around 32K tokens | Most academic users land here; Deep Research is the first ceiling hit |
| Pro $100 | $100 | 500 per month | 5x Plus limits, GPT-5.4 Pro | Expanded | Launched April 2026; bridges Plus and the $200 tier |
| Pro $200 | $200 | Effectively unlimited | GPT-5.5 Pro, Light and Heavy thinking | 1M tokens (around 680 pages) | Built for parallel deep dives, full-thesis context |
| Business | $25 per seat | Plan-dependent | Admin tools, no training on user data | Plan-dependent | Two-seat minimum; relevant only for labs and departments |
Pricing verified against OpenAI listings as of April 2026. The $20 Plus tier has held its price since 2023, while the product around it has expanded considerably.
Features that move the needle for academic work
| Capability | What it does | Why it matters in research |
|---|---|---|
| Deep Research | Autonomous agent that browses, reads, and writes a multi-source report | Closest ChatGPT gets to literature scoping; 5 to 30 minutes per run, capped at 10 per month on Plus |
| Canvas | Side-by-side document editor with inline AI edits | Useful for drafting paper sections, revising abstracts, restructuring arguments |
| 1M token context (Pro $200) | Holds roughly 680 pages of input | Permits feeding an entire thesis, supervisor feedback, and reference list in one chat |
| Custom GPTs and Projects | Saved instructions plus reusable files and tools | Locks in citation style, methodology framing, supervisor tone preferences |
| Codex agent | Code generation and execution environment | Strong on R, Stata, Python, statistical scripts tied to empirical work |
| File uploads | PDFs, datasets, transcripts up to several files at once | Lets the model annotate, summarize, and cross-reference source documents |
Strengths and where it falls short
| Strengths | Where it falls short |
|---|---|
| Reasoning quality on GPT-5.4 Thinking and GPT-5.5 Pro is materially ahead for structured argument and complex synthesis | Standard mode does not cite, and outputs read authoritatively even when wrong |
| Canvas and Projects accelerate the drafting phase from outline to revision | Plus users hit the 10-run Deep Research cap inside a single busy week |
| 1M token context on Pro $200 makes long-document research practical in one window | The $200 tier is hard to justify outside daily heavy-research workflows |
| Strong handling of math, statistics, and code review across major languages | Citation fabrication remains documented in peer-reviewed studies through 2025 and into 2026 |
| Memory and Projects retain context across sessions for ongoing research threads | Plus conversations may be used for model training unless training is opted out manually |
Best-fit academic use cases
| Use case | Verdict | Notes |
|---|---|---|
| Drafting and revising paper sections | Strong fit | Canvas plus GPT-5.4 Thinking is the standout combination |
| Outlining a thesis chapter from an existing reading list | Strong fit | Especially useful with files uploaded into a Project |
| Building statistical scripts in R, Stata, or Python | Strong fit | Codex agent handles execution and debugging in one loop |
| Generating a verified literature review with cited sources | Conditional fit | Use Deep Research only and verify every reference manually |
| Quick fact lookup with citation | Weak fit | Perplexity does this faster and with stronger source links |
| Translating technical material across languages | Strong fit | GPT-5.5 retains domain vocabulary across long passages |
Reviewer scorecard
| Dimension | Rating | One-line take |
|---|---|---|
| Reasoning depth | ★★★★★ | Best in class for structured academic argument |
| Drafting and writing quality | ★★★★★ | Canvas plus Projects is genuinely productive |
| Citation reliability (default mode) | ★★ and a half | Fabrication remains the documented failure |
| Citation reliability (Deep Research) | ★★★★ | Improved but still requires verification |
| Pricing accessibility | ★★★★ | $20 Plus delivers most academic value |
| Suitability for thesis-grade research | ★★★ and a half | Strong as part of a stack, not as a sole tool |
“ChatGPT can synthesize academic concepts beautifully. It explains methodology, critiques studies, and makes complex ideas digestible. The problem is that it will, with equal confidence, invent a citation that does not exist.”
Perplexity, Built Around Source Transparency
Perplexity was designed with citation as a default behavior rather than an optional add-on. Every answer arrives with numbered, clickable footnotes that link back to the original source. For an academic context, that single design decision changes the workflow. Verification stops being a separate step and becomes part of reading the answer.
The platform also runs in routed-model mode, meaning a Pro subscriber can choose responses from Claude Opus 4.6 or 4.7, GPT-5.4 or 5.5, Gemini 3.1 Pro, or Perplexity’s own Sonar models without juggling separate accounts. For researchers comparing how different models phrase the same conclusion, that consolidation matters more than it first appears.
Pricing breakdown for academics
| Plan | Monthly cost | Pro searches | Deep Research | Academic Focus | Notes for academics |
|---|---|---|---|---|---|
| Free | $0 | Around 5 per day | Limited | Restricted | Useful for testing only; throttled at peak hours |
| Education Pro | $10 via SheerID | Unlimited | 20 per day | Full access | Verified students and faculty; some carrier deals include 12 months free |
| Pro | $20 ($200 per year) | Unlimited | 20 per day | Full access | Standard researcher tier; includes $5 of Sonar API credits monthly |
| Max | $200 | Unlimited | Labs and Computer unlimited | Full access | Adds Labs research workflows, premium publisher data, Veo 3.1 video |
| Enterprise Pro | $40 per user | Unlimited | Unlimited | Full access | Shared Spaces, admin controls, SCIM provisioning at scale |
Pricing verified against Perplexity published rates as of April 2026.
Features designed for scholarly work
| Capability | What it does | Why it matters in research |
|---|---|---|
| Academic Focus mode | Restricts queries to Semantic Scholar’s 200M plus peer-reviewed paper corpus | Filters out blogs, news, Wikipedia; surfaces only journal-grade sources |
| Deep Research | Multi-step research workflow with 30 to 50 plus sources synthesized | Completes literature scoping in 2 to 4 minutes with inline citations |
| Spaces | Project-based research environments with persistent context | Holds a dissertation chapter, prior threads, and reference notes in one place |
| Premium data integrations | Statista, PitchBook, CB Insights, Wiley pulled into answers | Surfaces paywalled data inside responses with attribution |
| File upload analysis | Accepts PDFs, datasets, audio, and video as inputs | Pulls structured findings from uploaded papers and lecture transcripts |
| Pages and export | Outputs as Markdown, PDF, or shareable research reports | Hands research deliverables to advisors with linked sources intact |
Strengths and where it falls short
| Strengths | Where it falls short |
|---|---|
| Every answer ships with numbered, clickable citations by default | Source quality drifts toward news outlets unless Academic Focus is active |
| Academic Focus pulls from Semantic Scholar’s full corpus, not curated subsets | Coverage of non-English peer-reviewed literature lags Google Scholar |
| Deep Research completes in 2 to 4 minutes, far faster than competing tools | Synthesis can feel surface-level next to GPT-5.5 reasoning |
| Pro at $20 unlocks unlimited Pro Search plus 20 Deep Research runs daily | Labs research workflows are gated behind the $200 Max plan |
| Education Pro at $10 is the most affordable serious research subscription on market | A Tow Center analysis found around 37 percent of answers incorrect despite cited sources |
| Routed access to Claude Opus, GPT, Gemini, and Sonar from one account | Pro Search rate limits are intentionally undocumented; throttling can occur |
Best-fit academic use cases
| Use case | Verdict | Notes |
|---|---|---|
| Scoping a literature review for a new topic | Strong fit | Academic Focus plus Deep Research is the standard combination |
| Verifying a specific claim against peer-reviewed sources | Strong fit | Inline citations make this a 30-second check |
| Building a bibliography of recent papers in a niche | Strong fit | Semantic Scholar coverage stretches into long-tail journals |
| Drafting long-form analytical writing | Weak fit | ChatGPT or Claude produce stronger argumentation |
| Working with non-English scholarly sources | Mixed fit | Supplement with Google Scholar for regional journals |
| Statistical scripting and code generation | Weak fit | ChatGPT or Claude are stronger choices here |
Reviewer scorecard
| Dimension | Rating | One-line take |
|---|---|---|
| Source attribution and citation discipline | ★★★★★ | Defining strength of the product |
| Speed of response | ★★★★★ | Roughly 30 percent faster per query than ChatGPT |
| Academic source quality | ★★★★ and a half | Semantic Scholar integration carries the score |
| Reasoning and synthesis depth | ★★★ and a half | Solid but less interpretive than GPT-5.5 |
| Pricing accessibility | ★★★★★ | Education Pro at $10 is genuinely affordable |
| Suitability for thesis-grade research | ★★★★ | Strong with Academic Focus on, weaker without it |
“Perplexity reads fifteen to twenty papers in seconds and writes a 500-word synthesis with inline citations to each source. To get the same insight from Google Scholar would take four to six hours of reading abstracts.”
Attribution: Graduate research workflow benchmark, 2026
Head-to-Head Where It Counts
Headline pricing matches. Headline use cases overlap. The difference shows up the moment a researcher tries to do something concrete. Three dimensions tell most of the story: citation accuracy, speed paired with depth, and total cost of a usable workflow.
Citation accuracy and hallucination rates
Independent studies through 2025 and into 2026 keep returning to the same uncomfortable finding. AI tools fabricate citations more often than confident-sounding output suggests, and the rate varies dramatically by topic and model variant.
| Source study | Tool tested | Hallucination or error rate |
|---|---|---|
| Deakin University, mental health literature (2025) | GPT-4o (ChatGPT) | 19.9 percent fully fabricated; 56 percent contained errors |
| Walters and Wilder, Scientific Reports (2023) | GPT-3.5 and GPT-4 | GPT-3.5 fabricated 55 percent of cited works; GPT-4 fabricated 18 percent |
| JMIR systematic review analysis (2024) | GPT-4 across systematic reviews | 28.6 percent hallucinated references |
| Tow Center for Digital Journalism analysis | Perplexity | Around 37 percent of answers incorrect despite cited sources |
| Financial literature evaluation (2024) | GPT-4o and o1-preview | 20.0 to 21.3 percent hallucinated citations |
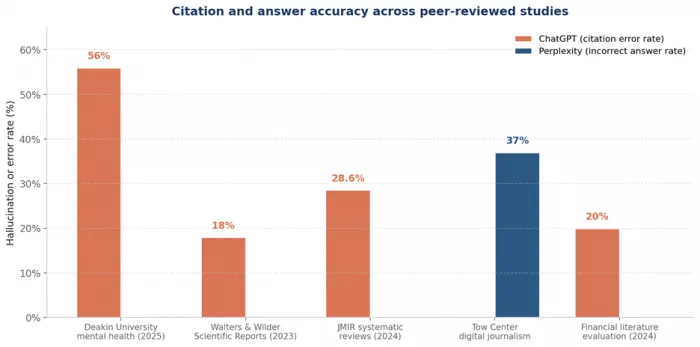
Figure: Citation accuracy across studies. Five peer-reviewed analyses, plotted on the same axis. The Tow Center number for Perplexity measures incorrect answers despite real citations.
The numbers cut both ways. ChatGPT in standard mode invents references that look real and survive a casual eye-test. Perplexity links to real sources but can still misread or misattribute the conclusion sitting inside them. Neither tool is safe to use without verification. Both are useful the moment verification is built into the workflow.
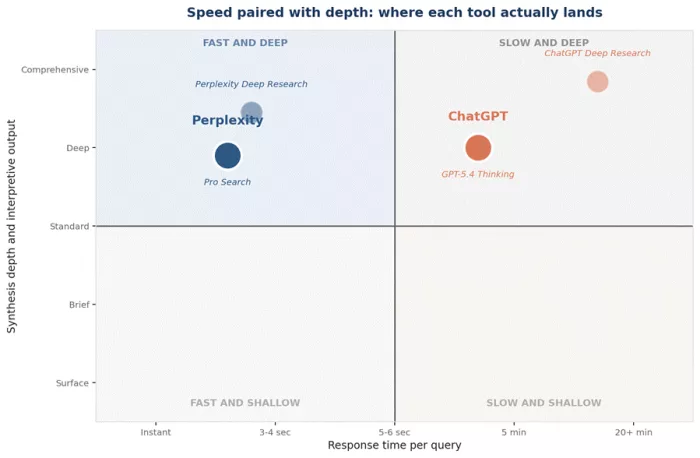
Speed and depth of synthesis
| Metric | Perplexity | ChatGPT |
|---|---|---|
| Average response latency per query | 3.8 seconds | 5.4 seconds |
| Deep Research completion time | 2 to 4 minutes | 5 to 30 minutes |
| Sources read per Deep Research run | 30 to 50 plus | 100 plus on Pro tiers |
| Citation density in output | High, inline, numbered | Variable, depends on Deep Research toggle |
| Synthesis style | Briefer, evidence-anchored | Longer, argument-driven |
| Best for | Discovery and verification | Interpretation and drafting |
For literature scoping, Perplexity’s speed advantage compounds across a research day. For interpretive depth, where the question is what a set of papers means rather than what they are, ChatGPT’s reasoning still pulls ahead.
Cost per useful output for a graduate researcher
| Workflow | Tool stack | Monthly cost |
|---|---|---|
| Literature scoping only | Perplexity Education Pro | $10 |
| Drafting and revision only | ChatGPT Plus | $20 |
| Full thesis workflow (most common in 2026) | Perplexity Education Pro plus ChatGPT Plus | $30 |
| Heavy daily research load | Perplexity Pro plus ChatGPT Pro $100 | $120 |
| Unlimited everything | Perplexity Max plus ChatGPT Pro $200 | $400 |
How Serious Researchers Are Combining Both
The cleanest workflow seen across academic users in 2026 reads almost like a checklist. Each step uses one tool for the thing it is genuinely good at, and stops using it the moment the work moves into another tool’s strength.
| Step | Action | Tool and rationale |
|---|---|---|
| 1 | Scope the literature on the chosen topic | Perplexity with Academic Focus on. Pro Search or Deep Research surfaces seminal papers with live source links. |
| 2 | Verify the top five to ten sources directly | Google Scholar or publisher site. AI citations are starting points, not endpoints. |
| 3 | Synthesize the verified PDFs into a working argument | ChatGPT Project with GPT-5.4 Thinking or GPT-5.5. The 1M token context (Pro $200) holds everything in one place. |
| 4 | Draft and iterate section by section | ChatGPT Canvas. Inline edits and side-by-side revisions cut the rewrite cycle in half. |
| 5 | Fact-check specific claims before submission | Perplexity. Inline citations make verification a 30-second loop, not a half-hour detour. |
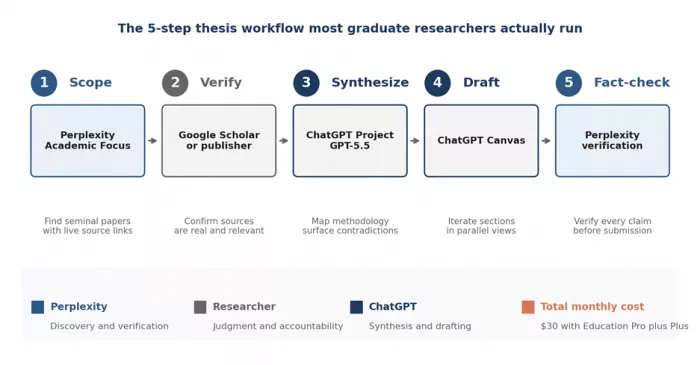
Figure: The five-step research workflow. Each tool used only for what it does best, with the researcher holding judgment and final accountability throughout.
The sequence treats each tool as good at exactly one thing. Perplexity handles discovery and verification. ChatGPT handles synthesis and drafting. The researcher handles judgment and accountability, which is still the part no AI tool has earned the right to take over.
Where Each Tool Falls Short
Honest reviews matter more in 2026 because the marketing tone around AI research tools has lost most of its connection to the actual product. Both platforms are worth subscribing to. Both also have specific failure modes that any researcher relying on them should be ready to spot.
| ChatGPT honest weaknesses | Perplexity honest weaknesses |
|---|---|
| Standard mode still fabricates citations, with peer-reviewed studies finding fabrication rates between 18 and 56 percent depending on topic and model variant | Source quality drifts toward news outlets and aggregators outside Academic Focus mode |
| Plus users hit the 10-run Deep Research cap inside a single busy research week | Coverage of non-English peer-reviewed work, particularly Arabic, Mandarin, and regional European journals, lags Google Scholar |
| Pro pricing climbs steeply, with the $200 tier hard to justify outside daily heavy-research workflows | Synthesis on complex theoretical questions reads thinner than ChatGPT or Claude |
| Plus conversations may be used for model training unless training is manually opted out, which matters for unpublished work and confidential interview data | Labs research workflows are locked behind the $200 Max plan, putting deeper agentic research out of reach for most academics |
| Deep Research occasionally treats speculative blogs as authoritative sources, and there is no native mode that limits the corpus to peer-reviewed material | Despite citing real sources, the 37 percent incorrect-answer rate reported by the Tow Center means a citation link is necessary but not sufficient evidence that the claim is right |
Both tools have moved faster than peer review can keep up with. The right reflex for any serious researcher is to assume both will mislead at least once per session and to design the workflow around catching it before the citation makes it into a draft.
Closing Read
The Perplexity vs ChatGPT question rarely resolves cleanly because the tools are not actually competing for the same slot in a research workflow. One is a citation engine that happens to talk. The other is a reasoning engine that happens to search. Asking either to be the other surfaces the most-cited weaknesses in both.
For 2026, the verdict that holds up across thesis writers, journal editors, and laboratory PIs is this. Subscribe to both at the standard tier. Lean on each for its strongest function. Treat every citation either tool produces as a hypothesis worth verifying. The combined $30 monthly cost still comes in below a single conference registration, and the protection it buys against a fabricated reference making it into a published paper is genuinely hard to overstate.
Comments