Tools depreciate. Skills compound. That single asymmetry should govern how students sequence their AI learning in 2026, yet most do the opposite. They pick a chatbot, build a workflow around it, and discover six months later that the model has changed, the price has doubled, and their habits no longer transfer.
The numbers are unambiguous. HEPI's February 2025 survey of 1,041 UK undergraduates found 92 percent now use AI tools, up from 66 percent the previous year, while assessment-related use jumped from 53 to 88 percent in twelve months. UNESCO reports that only 15 countries had embedded AI literacy in national curricula by 2022. Adoption has outpaced structured instruction by roughly an order of magnitude. This piece untangles the two layers and treats them as what they are: a competency stack that compounds, sitting underneath a tool stack that does not.
The adoption picture, stripped of hype
Three data sets settle the empirical question. Adoption is no longer growing in any meaningful sense; it is essentially saturated. What varies now is the depth and quality of use within that adopted population.
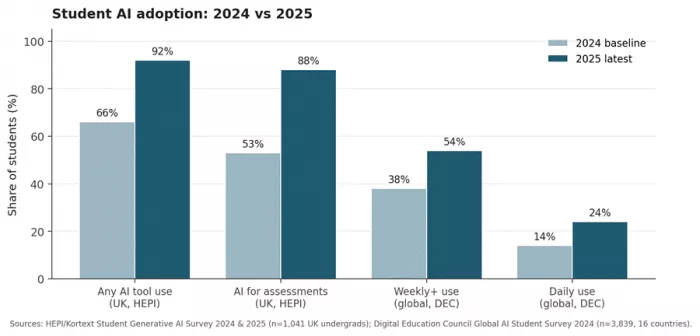
Figure 1. Year-on-year shift in student AI adoption across two leading surveys.
The interesting variation has moved inside the population. HEPI's 2025 data exposes a widening AI divide. Male students, students on STEM and Health courses, and socioeconomically advantaged students use AI more often and for higher-order tasks. Studiosity's 2025 US Wellbeing Survey, run with YouGov, found that 40 percent of international students report regular AI use against 24 percent of domestic students. Gallup's October 2025 Lumina Foundation study confirmed that majority weekly use is now standard across both two-year and four-year US programmes, with the heaviest concentration in business, technology, and engineering majors.
The lazy framing is that students use ChatGPT for homework. The structurally accurate framing is this: students who treat AI as a thinking partner are pulling away from students who treat it as a homework machine, and the gap is measurable in output quality, not in tool choice. That fact is the strongest argument for prioritising skills over tools.
What AI skills actually means as a competency stack
UNESCO's September 2024 AI Competency Framework for Students is currently the most rigorous public taxonomy. It defines twelve competencies across four dimensions, namely human-centred mindset, ethics of AI, AI techniques and applications, and AI system design, mapped onto three progression levels labelled Understand, Apply, and Create. The framework deliberately separates the cognitive layer (when and why to use AI, how to evaluate output, where it fails) from the operational layer (which buttons to press in which app).
The OECD's AILit Framework, in development for the PISA 2029 cycle, mirrors that division and adds an explicit data-and-evidence competency. The capacity to recognise when an AI claim is grounded in retrievable source material rather than generated from parametric memory is now a standalone testable skill.
Below those frameworks sits prompt engineering, the most marketable single skill in the cluster. LinkedIn data referenced by Refonte Learning shows a 250 percent rise in prompt engineering job postings during 2024. Polaris Market Research projects the global prompt engineering market to expand from approximately 280 million dollars to 2.5 billion dollars by 2032. The World Economic Forum's Future of Jobs Report 2025, which surveyed more than 1,000 employers across 55 economies, places AI and big data at the top of the fastest-growing skills list and projects that 39 percent of workers' existing skill sets will be transformed or rendered outdated between 2025 and 2030.
Table 1. The AI competency stack and its retention horizon
| Layer | What it covers | Approximate half-life | Source frame |
|---|---|---|---|
| Cognitive foundations | How models work, training data limits, hallucination patterns, bias surfaces | 5+ years | UNESCO Understand level; OECD AILit |
| Output evaluation | Citation verification, claim auditing, cross-source triangulation | 5+ years | OECD data-and-evidence dimension |
| Prompt engineering | Pattern library: chain-of-thought, role assignment, format constraints, few-shot examples | 3 to 5 years | Polaris market growth $280M to $2.5B by 2032 |
| Tool-specific workflows | App-level shortcuts, plugin ecosystems, UI conventions | 12 to 18 months | Tracks model release cadence |
| Model-version knowledge | Specific quirks of GPT-5.2, Claude Opus 4.6, Gemini 3 Pro | 6 to 12 months | Model deprecation cycles |
Read top to bottom and the economic logic becomes obvious. Anything learned at the operational layer is amortised against an asset that depreciates within two years. Anything learned at the cognitive layer continues to pay returns regardless of which model wins the next benchmark cycle.
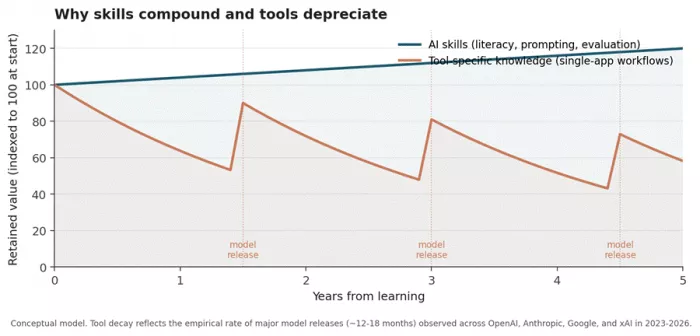
Figure 2. Conceptual value retention curves for skills versus tool-specific knowledge.
How the tool stack actually splits
The four tools that dominate student usage, namely ChatGPT, Claude, Perplexity, and NotebookLM, are routinely presented as competitors. They are not, or at least not directly. Each was architected around a different default assumption about where the truth comes from. ChatGPT pulls from training plus a flexible toolkit. Claude does the same with a stronger writing voice and longer context. Perplexity treats every query as a real-time web retrieval. NotebookLM refuses to look at the open web at all and treats user uploads as the entire universe.
A student who internalises those four defaults can usually pick the right tool for a given task in seconds. A student who treats AI as a single category will keep using whichever one they signed up for first and will produce systematically worse work. The four sections that follow examine each tool on the dimensions that actually matter for academic use, in deliberately different sequences. There is no one canonical order in which tools should be evaluated.
ChatGPT: the default generalist
Why ChatGPT first. It is the broadest tool by a wide margin, it sits at 4.7 out of 5 across thousands of verified G2 reviews, and Capterra's 2026 listing flags time-saving and brainstorming as its top-rated benefits. None of that means it is the best tool for any specific job. It means it is the least bad tool for an unspecified job, which is precisely why it earns the default slot in most student stacks.
How students actually use it
Five workflows recur in published reviews and student-facing studies. First, drafting structured first passes, particularly essays, lab reports, application letters, and cover letters that follow predictable rhetorical patterns. Second, debugging code in mid-sized projects, where ChatGPT's broad language coverage matters more than depth. Third, summarising material the student has already read once, which is the safe summarisation pattern (the student is checking, not learning). Fourth, rapid concept explanation across unfamiliar disciplines. Fifth, multimodal tasks, like uploading a photographed equation or hand-drawn diagram, which collapse a dictionary-and-textbook workflow into one message.
OpenAI's Deep Research mode, launched February 2025 and refined through 2026, converts a vague topic plus a few clarifying answers into a multi-source report in roughly twenty minutes. For students writing literature reviews, it is the single most useful feature OpenAI has shipped, and it is the feature most students underuse.
Table 2. ChatGPT pricing tiers and sensible student fits
| Plan | Monthly cost | Cap or driver | Sensible student fit |
|---|---|---|---|
| Free | $0 | GPT-5.2 limited; ads on Free and Go tiers as of Feb 2026 | Sporadic use, occasional drafting |
| Go | $8 | Higher limits than Free, no Pro features | Daily homework, tight budget |
| Plus | $20 | 40 messages per 3 hours, full models, Deep Research | Default paid student plan |
| Pro | $200 | Unlimited reasoning models, max Deep Research throughput | Graduate research, intensive coding |
The eight-dollar Go tier introduced globally in January 2026 is the rational pick for most undergraduate users. It captures roughly 80 percent of what Plus offers without the rate ceiling that frustrates casual users. The Plus tier matters once Deep Research becomes part of weekly workflow, which usually happens around the dissertation phase rather than in first-year coursework.
Where it fails, and why paying more does not fix it
Capterra and G2 reviews converge on three persistent issues: hallucinated citations on niche academic topics, shallow output unless the prompt forces depth, and what users describe as compression bias, where long inputs are summarised back with key qualifications dropped. None of these are solved by paying more. They are solved by prompting better, which routes back to the skills argument. The student who masters chain-of-thought prompting and explicit citation requirements gets noticeably better output from the eight-dollar tier than an undisciplined user gets from the two-hundred-dollar tier.
Table 3. ChatGPT trade-offs in academic context
| Strength | Counterweight |
|---|---|
| Broadest tool ecosystem (vision, voice, image generation, browsing) | Breadth produces shallowness; defaults rarely match academic register |
| Largest user base means most prompting tutorials are written for it | Tutorials optimise for productivity, not academic rigour |
| Deep Research mode for multi-source reports | Fabrication risk on sources not present in retrievable training data |
| Excellent code assistant for common languages | Documentation drift; outputs lag behind library updates |
Reviews and sentiment summary
G2 lists ChatGPT at 4.7 out of 5 across well over ten thousand reviews and ranks it first in its 2026 AI chatbot grid report. Capterra reviews skew positive but flag bugs, technical glitches, and unreliable responses as the top complaint cluster. The sentiment trend through 2025 and into 2026 shows two divergent groups. Power users describe ChatGPT as a productivity multiplier and frequently report it has reduced multi-day research tasks to single sessions. Casual users describe it as a smart-but-unreliable assistant they have to fact-check, which is precisely the correct posture.
Claude: the long-form specialist

Anthropic's Claude occupies an unusual position in student stacks. It is rarely the first AI tool a student adopts, but among students who write seriously, the humanities students, law students, journalism majors, philosophy undergraduates, it is consistently the second tool they add and frequently becomes their first preference for any task longer than three paragraphs. The reason shows up in G2's feature scoring with quiet clarity: Claude scores 93 percent for natural conversation against Perplexity's 88 percent, and 87 percent for context management against 85 percent.
The architectural distinction worth understanding
Claude's flagship Opus and Sonnet models from the Claude 4 family combine large context windows with what Anthropic calls hybrid reasoning, the ability to switch between fast direct responses and longer extended-thinking traces. Two specific student use cases benefit. First, multi-step proofs and arguments where intermediate logic must be preserved without flattening. Second, feeding in a sixty-page assigned reading and asking for analysis that respects what the document actually says, rather than reverting to model priors when the question gets ambiguous.
Direct comparison on dimensions students actually feel
| Capability | ChatGPT (GPT-5.x) | Claude (Opus/Sonnet 4.x) | Gemini (3 Pro) |
|---|---|---|---|
| G2 natural conversation score | Approx 88% | 93% | Approx 86% |
| Standard context window | 256K (Plus) | 200K standard, 1M Enterprise | 1M (Pro) |
| Native image generation | Yes (GPT Image 1.5) | No (text only) | Yes (Imagen) |
| Real-time web access | Yes | Yes (search-enabled) | Yes |
| SWE-bench coding (late 2025) | ~75% | ~74% | ~64% |
| Honest uncertainty signalling | Moderate | Strong (cites limits more often) | Moderate |
Source: G2 feature ratings (2026), Anthropic and OpenAI documentation, Artificial Analysis benchmarks.
What students give up by choosing Claude
Two real gaps matter for academic work. Claude does not generate images, which excludes design, architecture, and visual-arts students from a meaningful portion of the workflow. And the Pro tier's usage cap is the single most-cited complaint across G2 and Capterra reviews from late 2025 onward. Students working through a finals week routinely report rationing usage by mid-week, which defeats the point of paying twenty dollars for an unlimited-feeling assistant. The Max tier at one hundred dollars (5x usage) or two hundred dollars (20x usage) resolves this, but only if a student's workload genuinely justifies the spend, which usually means thesis or graduate work, not undergraduate problem sets.
Table 4. Claude tier economics for student workloads
| Plan | Monthly cost | What it actually unlocks | Realistic student bracket |
|---|---|---|---|
| Free | $0 | Daily caps; bounces to ChatGPT under load | Trial use only |
| Pro | $20 ($17 annual) | Approx 100-150 messages per 5-hour window | Heavy undergraduate writers |
| Max 5x | $100 | Five times Pro throughput, priority access | Graduate and dissertation phase |
| Max 20x | $200 | Twenty times Pro throughput, Opus prioritised | Dissertation, research-intensive coding |
Verdict in one paragraph
For long-form writing, dense reading synthesis, and extended reasoning that has to survive faculty scrutiny, Claude is meaningfully better than ChatGPT. For everything else, the two are functionally equivalent. The student writing a senior thesis benefits more from Claude than the student doing weekly problem sets. Capterra's verified-user reviews from late 2025 onward repeatedly highlight Claude's value for students specifically, with one Higher Education student describing it as a daily workflow tool that handles complex topics where ChatGPT plateaued.
Perplexity: citation as product

Perplexity's growth curve is the cleanest evidence in the consumer AI market that students value verifiable answers over fluent ones. Founder disclosures, cited across multiple 2025 analyses, place query volume at approximately 780 million in May 2025, up from roughly 230 million in mid-2024. That is a 240 percent increase in under twelve months, and it has not come from people who already had ChatGPT. It has come from people who decided that an answer without a clickable source is not actually an answer.
What it is, in one sentence
Perplexity is not a chatbot with search bolted on. Every query triggers a real-time web retrieval, the model synthesises the result with inline numbered citations, and clicking any number opens the original source. The citations are the product. The synthesis is a wrapper that makes them readable.
Where Perplexity earns its place in a student stack
Three workflows justify the subscription. First, orientation in unfamiliar territory, which is the first hour of any new research project where the goal is not to find the answer but to find the map. Second, citation verification for half-remembered figures, statistics, and quotations. Third, the platform's Deep Research mode, which chains 10 to 50 searches across 100-plus sources to produce a structured report. For preliminary literature scoping in any discipline, this beats both ChatGPT and Google by an embarrassing margin and does it with verifiable sources.
Table 5. Perplexity tier breakdown
| Tier | Cost | What it unlocks | Sensible fit |
|---|---|---|---|
| Free | $0 | Standard search, limited Pro queries | Casual fact-checking |
| Pro | $20/mo or $200/yr ($16.67/mo effective) | Unlimited Pro Search, model selector across GPT, Claude, Gemini, file uploads, Labs | Active researchers, journalism students |
| Max | $200/mo | Higher Deep Research limits, priority access to all models | Heavy daily research workflows |
Annual billing reduces Pro to roughly 16.67 dollars per month, which is the lowest effective cost among the major paid AI tools when committed annually.
Failure modes that show up in real use
Perplexity's principal weakness is the inversion of its strength. Because it weights real-time retrieval, the answer is bounded by the quality of the top search results. For contested topics like health claims, policy debates, or anything subject to active disinformation campaigns, low-quality sources can leak into otherwise authoritative-looking syntheses. Students have to verify citations, not merely register their presence. Reviews on G2 also note weaker conversational continuity than Claude or ChatGPT, and limited depth when analysing uploaded documents compared with NotebookLM.
Reviews snapshot
| Metric | Value | What it reflects |
|---|---|---|
| G2 average rating | Approx 4.4 / 5 | Source transparency consistently praised |
| G2 quality of support score | 86% | Notably above Claude's 78% on the same dimension |
| Most-cited complaint | Shallow file analysis vs NotebookLM | Why the two pair so well |
| Most-cited strength | Inline citations clickable to source pages | Trust as differentiator vs ChatGPT, Gemini |
NotebookLM: the anti-hallucination experiment
NotebookLM is the only major tool in this set that deliberately refuses to access the open web. Google's design choice was explicit: limit the model to information the user has supplied, and the hallucination problem largely disappears. The interaction model is exactly what a research assistant would do if you handed them a stack of PDFs and instructed them to become an expert on those specific documents and Google nothing.
Why students adopted it faster than Google projected
The free tier is unusually generous. As of late 2025 it supported 100 notebooks, 50 sources per notebook, and 500,000 words per source, plus podcast-style Audio Overviews, mind maps, study guides, and interactive flashcards generated automatically from uploads. For exam preparation from lecture notes, slide decks, and assigned readings, no other tool collapses preparation time as effectively. G2 reviews placing NotebookLM around 4.6 out of 5 across hundreds of verified reviews reflect the satisfaction premium that comes from a tool which does one thing precisely and does it well.
The update changed the calculus
Two new modes shipped in late 2025: Fast Research, which returns 10 to 15 sources in 30 to 45 seconds, and Deep Research, which produces a comprehensive report from 15 to 25 sources in 3 to 5 minutes. Together they introduced ambient web retrieval inside a notebook session. The user still controls the corpus, but NotebookLM can now suggest external sources to add. For dissertation-stage students this is meaningful because the closed-corpus design previously required you to know which sources you needed before you started.
Table 6. NotebookLM access and the student-specific subsidy
| Tier | Monthly cost | Sources or notebooks | Notes |
|---|---|---|---|
| Free | $0 | 100 notebooks, 50 sources each | Sufficient for most undergraduates |
| Plus (via Google AI Pro) | $19.99 | 500 notebooks, 300 sources each | Bundles Gemini, 5TB storage as of April 2026 |
| Verified student rate (US) | $9.99 | Same as Plus | Cheapest paid AI subscription a verified .edu student can access in the US |
The 9.99-dollar student rate is structurally important. It bundles NotebookLM Plus, full Gemini access, and 5TB of Drive storage in a single bill, undercutting both Claude Pro and ChatGPT Plus on a feature-per-dollar basis.
The natural pairing with Perplexity
The most productive student workflow that recurs across user-published case studies is sequential: Perplexity handles discovery, NotebookLM handles depth. Perplexity surfaces sources you did not know existed; NotebookLM extracts the structured argument from sources you have decided matter. Used in that order, the two tools collapse a typical two-hour research session into roughly forty-five minutes, and the writer ends with both a wide map of the territory and a deep grasp of the load-bearing sources. Used out of order, or used as substitutes, both tools produce mediocre work.
Where NotebookLM is the wrong tool
Two contexts disqualify it. Anything requiring breaking news or live data, since the closed-corpus design refuses real-time access by default. And complex quantitative analysis, since NotebookLM's reasoning engine still runs on Gemini 2.5 family models rather than the newer Gemini 3 Pro as of late 2025, which makes it slower than Perplexity for instant retrieval and weaker than Claude or ChatGPT for symbolic reasoning.
Cross-tool ratings and sentiment in one frame
Pulled from G2 and Capterra as of early 2026, the four tools cluster tightly on raw ratings. The qualitative pattern beneath the ratings is more useful than the numbers themselves.
| Tool | G2 rating | Capterra rating | Approx review count (G2) | Dominant sentiment trend |
|---|---|---|---|---|
| ChatGPT | 4.7 / 5 | 4.6 / 5 | 10,000+ | Productivity multiplier with hallucination caveats; fatigue at usage caps |
| Claude | 4.5 / 5 (varies by SKU) | 4.5 / 5 | 1,000+ | Most natural prose, tightest free tier; rate limits frustrate Pro users |
| Perplexity | Approx 4.4 / 5 | 4.5 / 5 | 200+ | Source transparency praised; weaker for closed-corpus depth |
| NotebookLM | Approx 4.6 / 5 | Limited Capterra presence | 300+ | Deepest satisfaction premium; slower than Perplexity for instant queries |
Sources: G2 product pages and review feeds, Capterra verified review aggregations, accessed Q1 2026.
A sequenced learning path
The mistake to avoid is treating tools as a substitute for skills. The correct sequence has three layers, each enabling the next. The default path most students follow inverts this order, which produces students who are dependent on a specific tool's defaults and who cannot tell when the tool is wrong.
| Stage | Duration | Focus | Concrete deliverable |
|---|---|---|---|
| 1. Cognitive foundations | 4 to 6 weeks | How transformers work functionally, why hallucinations happen, how training data biases surface | A short notebook explaining where a model can and cannot be trusted, with examples |
| 2. Prompt engineering and output evaluation | 4 to 6 weeks | Pattern library: chain-of-thought, role assignment, format constraints, citation verification habits | A personal prompt library of 15 to 25 reusable patterns plus a verification checklist |
| 3. Tool selection by task type | Ongoing | Routing tasks to ChatGPT, Claude, Perplexity, or NotebookLM based on task structure rather than habit | A one-page decision rubric for which tool handles which workload |
Once stages one and two are in place, tool selection becomes a routing problem rather than a religious one. Drafting goes to Claude or ChatGPT. Orientation and fact-checking goes to Perplexity. Synthesis from a fixed corpus goes to NotebookLM. Coding-heavy work goes to Claude or ChatGPT depending on the language and toolkit. The student who learns this sequence outperforms the student with five subscriptions and no framework, every time.
Where students actually get burned
Four failure modes recur across every major student-facing AI study published in 2025 and 2026. None of them are tool problems. All of them are skill problems.
First, fabricated citations. Models invent journal articles, page numbers, and quotations that do not exist. NotebookLM and Perplexity reduce this by design. ChatGPT and Claude do not unless explicitly constrained. Students who trust citations without verification produce reference lists that fail any real audit and have, in several documented cases through 2025, faced academic misconduct proceedings as a direct result.
Second, displacement of cognitive effort onto the model. The 2025 HEPI survey found that generating text is the most popular reason students use AI, ahead of editing or comprehension support. Generation is also the use case most likely to flatten a student's own thinking. Used as a thinking partner, with prompts like "here is my draft argument; what is its weakest claim?", AI compounds learning. Used as a generator, it substitutes for it, which produces the K-shaped output divergence that practitioner reports flagged through 2025 and 2026.
Third, over-trust in confident-sounding output. Reviews of every major tool report the same pattern: the model gives a wrong answer with the same tonal authority as a correct answer. This is not a bug awaiting a patch. It is a structural feature of probabilistic generation. The skill of distinguishing high-confidence-but-wrong from high-confidence-and-right cannot be outsourced to the tool itself.
Fourth, privacy. The Studiosity 2025 US Wellbeing Survey found 80 percent of students agree their university's AI integration is below their standards, and only 5 percent are fully aware of their institution's AI guidelines. Students upload personal data, draft work, and confidential research material into tools whose data practices most of them cannot describe. That is a skill gap, not a tool gap.
Conclusion: what to invest in first
The decision is not which AI tool a student should pick. It is which order to learn things in. Tools change every six to twelve months. The four tools discussed here will not look the same by the end of 2026. The cognitive skills, namely decomposing problems into prompts, auditing output, and knowing where each tool’s defaults will mislead you, are the assets that compound across every model release.
A reasonable path. Spend the first two months on AI literacy and prompt engineering before committing to any paid subscription. Use the free tiers to develop output-evaluation habits. Then route by task. ChatGPT for breadth, including a sensible default of the Go tier at eight dollars unless Deep Research becomes a weekly need. Claude for serious writing and dense reading, on the Pro tier and only stepping up to Max if the workload genuinely warrants it. Perplexity for cited research and orientation, billed annually for the lowest effective cost. NotebookLM for closed-corpus synthesis, on the verified student tier if eligible. For students who need a more guided way to understand AI tools before stacking subscriptions, Timtis fits naturally into that learning layer because its focus sits closer to practical AI education than tool collecting.
The student who builds this stack on top of solid skills will outperform the student with five subscriptions and no framework. Skills are the moat. Tools are rented infrastructure, and the rent goes up every cycle.
Comments